大家好,感谢有这样的机会,跟大家分享科亿在深度学习落地工业检测领域的经验。我今天主要分享两个方面的内容,第一个是如何在样本数量不足的情况下,训练一个可以在现场部署的神经网络模型,第二个是工业检测领域里面嵌入式的应用。

首先,介绍一下科亿的历史背景,科亿是一家专注于人工智能技术(AI)研发及产品推广应用的国家级高新技术企业。早在2004年就进入了工业检测领域,主要是做色选机,到2015年,人工智能深度学习越来越多的应用了,当时我在高校,对人工智能的进展有一定的了解,也看到深度学习在工业检测领域将会取得突破,而我对工业检测也比较感兴趣,一直在做这方向的研究,所以就加入了这个团队。
我们团队之前是在泰禾光电,在泰禾光电的时候就已经设计研究了全球首款基于人工智能的分选设备,当时是用于法国细豆角的检测,用的是人工智能深度学习模型训练,后面会有相关案例的详细介绍。
科亿算是二次创业,去年我们团队股权收购了科亿,把新的人工智能技术用在科亿的老业务上,科亿原来是做传统色选和包装检测的,当我们把人工智能技术应用在这个行业,取得了非常显著的效果。

接下来,介绍一下科亿的团队,颜天信博士是我们总经理,我与汪增福老师、曹洋博士负责算法方面,唐麟博士负责光学方面,黄炜博士负责交易软件方面,我们的团队配备比较全,核心成员在光机电领域都是带头人,我们的强项是算法。

科亿有四个产品方向,第一个是品质控制,这是我们主要的方向,经过一年多的发展,目前已经在20多个细分行业应用,这也充分证明了我们的算法泛化能力相当不错;第二个是文字识别,虽然这块现在有很多公司在做,但科亿在这方面也有一定的优势资源;第三个是物联网+AI,这是我们目前在布局的方向;第四个是资源回收,也是我们的老本行。

我们目前的重点是品质控制,主要应用是在缺陷检测和分类分级方面。科亿的发展是双轮驱动的,从专有特定行业来制定专用算法,然后在专用算法上提炼AI平台,最后再把AI平台应用到其他行业进行泛化,这是我们的发展策略,所以在应用初期我们选的基本上是各个细分行业,然后再慢慢拓展至整个大行业。目前,新能源领域也是这样布局。

在发展过程中,我们提炼了KVS-AI算法平台,这个AI算法平台提供三种不同级别的训练版本,分别是免费级的通用客户评估版本,客户自训级的行业客户训练版,以及客户定制级的类人识别级算法版本,三种不同级别分别对应不同的客户。

上图是一个实际操作的案例,跟很多公司大同小异,都是标注、训练、部署的流程,但也有比较特别的,这就是今天要讲的第一个内容——数据增强。

数据增强是深度学习落地过程中必不可少的环节,工业检测领域的数据量非常多,但缺陷样本不多,缺陷样本的收集又是一个漫长的过程,如果要等缺陷样本收集全再落地,所有公司都等不了,这种情况下用典型样本收集就比较方便,也就是客户提供一些典型样本,我们在只有少量典型样本的情况下,生成一个在现场部署的模型,等进入现场应用环节以后,数据就非常多了,再通过连接生产线的方式,获得大量现场数据,再优化模型就比较方便了。
那么,如何在数据有限的情况下,获得一个能够快速部署的模型呢?这里介绍一下我们的经验。

首先,将模型框架分成两部分,第一部分是数据合成模块,首先进行种子样本的提取,其次是种子样本的挑选,最后再用种子样本来进行数据合成,第二部分是分选模块,分别是分类定位和着力点分析。

在实际应用环节,要在合成数据上训练部署,以线阵相机为例来说明一下这个过程,线阵相机里面是连续数据流,从连续数据流中提取合适的种子,从而获取实时物料样本。

这是一个2018年细豆角检测的应用案例,需要把没有剪掉的芽头识别出来。法国的机械化程度高,不像我们是人工摘菜,他们是工业化生产用机器切,但是有一些没办法切到,他们希望把没切到的豆角芽头挑出来,要求在1:1的情况下做到95%以上的精度,这个用传统型选的方法难度比较大,精度不高,很难达到客户的需求。
当时,我们把深度学习技术用在了这个项目上面,在数据里挑选了一批种子样本,这批种子样本是机器来自动挑的,不是人工,机器挑完以后进行手动标注,标注种子样本上的缺陷位置,形成标注图,然后就得到原图、掩膜图和缺陷图三种图。
得到这三种图以后,再进行数据的自动合成,合成各种种子的粘连样本,在分选的时候,最麻烦的就是样本的粘连,粘连的情况非常复杂,所以粘连样本要合成得足够多,才能得到比较好的效果,所以我们合成了大量的样本。
深度学习里面有GAN这种数据合成手段,但是在这里GAN并不合适,因为合成完以后还需要标注,用我们这种合成方法,可以很快速的把缺陷位置标注出来,合成大量的缺陷样本,样本合成完以后,接下来就是训练了,在训练方面大家都是行家,这里就不展开讲了。
这个项目最终的效果相当不错,在2018年底的时候,我们就推出了基于深度学习的分选机,直接拿到法国现场用。当时是用6台1080Ti做应用,造价非常高,所以我们就在想深度学习的优势在哪里?后来我们跟米文动力结成了战略合作伙伴,在这方面米文动力对我们的帮助非常大。

上图是其他应用场景里面合成的图片,如果不说,大家可能看不出来哪个是合成的,精度非常高,所以用这种图像进行训练,然后去现场部署模型,性能差别不会太大,部署到现场以后,获取大量的数据,再进行新数据的生成,新数据的获取,新模型的获取,经过这样快速迭代以后,落地就快了。

除了数据增强方面的能力,我们的网络模型也很优秀,网络模型速度和处理速度都非常快,比如在异纤行业里面,图像是400*400,1毫秒可以完成前向,速度非常快,泛化能力也非常不错。
除此之外,我们还有全栈开发的能力,可以做相机、采集卡以及硬件设备等等,同时我们也有光学博士,具有视觉设备全栈开发能力。
同时,我们也非常注重算法与算力的融合,我们认为深度学习,不应该只对硬件进行推广,显然边缘端的算力不足以来承担非常大的模型,所以在部署边缘端算法的时候,要注意算法层次的设计,这也是等一下要讲的嵌入式方面的应用。

在设计过程中,我们分析了几种结构,第一种是用工控机+GPU,这种是大家用的最多的了,目前大概有百分之八九十的部署应用,都是用工控机来进行实现的。
它的优势比较明显,可以同时接很多路设备,在实际应用场景里面,1台工控机最多可以接了24路相机。但这种方式,也存在一些问题,首先GPU用显卡来进行前向是英伟达不推荐的,其次显卡的迭代非常快,比如去年我们推出了基于2080Ti的设备,今年2080Ti就已经停产,买不到了。这种情况下,我们需要向客户解释为什么设备需要换一个型号,客户也并不希望设备频繁更换核心零部件,所以用工控机+GPU的方式,并不是最好的选择,它的性价比很低。

第二种是嵌入式(AI芯片),也是今天要重点介绍的解决方案。嵌入式的优势,像米文动力EVO系列采用的无风扇设计,在很多场景里面都有非常大的优势,且算力都不低,比如MIIVII EVO Xavier,算力达到了32Tops,完全可以满足工业场景的应用。
很多工业场景的环境非常恶劣,用工控机不可能实现,比如异纤检测,这个场景是全封闭的,热量出不去,用工控机来进行检测,到夏天基本上就受不了,我们去年推了几十台这样的设备,到今年夏天就频繁告急。嵌入式就没这个问题,是一个比较大的优势,虽然成本比工控机要高一些,但也是可以接受的,像MIIVII EVO Xavier,我们用1台设备接4路千兆相机,性价非常高。

第三种是分布式边缘计算,色选方面基本上用的都是分布式边缘计算的架构,里面总共有10个通道,每个通道都是独立计算的,扩展起来非常方便,这也是我们目前正在力推的分布式边缘计算。
当然,米文也有适用于这种场景的产品——米文动力X架构分布式边缘计算,这是我们双方正在进行合作的项目,算力方面基本上没有什么问题了,算法之前晓楠总介绍了很多,英伟达在嵌入式市场部署方面有很丰富的经验,可以带来比较大的性能提升,经过英伟达的快速部署,用在这种超实时场景里面,完全没有问题。

目前,我们的设备已经在很多行业应用了,比如纺织、印刷、工业互联网、3C、工业零部件等基本上都有涉足,另外像传统包装行业用的也非常多。

在文字识别场景,用的是智能相机OCR系统,OCR系统有两个优势,第一个是可以用极小样本进行学习,第二个是超高识别精度,高达99.99%。在物联网+AI场景,我们正在积极布局,目前跟海螺集团和蔚来工厂都有合作,是些5G+AI的应用场景。
目前,我们有四种机械架构可以应用在不同的行业,分别是通用表检类(皮带传送),通用表检类(玻璃转盘),品质分析类和分选类。

通用表检类(皮带传送),用于各种包装检测行业

通用表检类(玻璃转盘),用于纽扣、密封圈等零部件检测行业

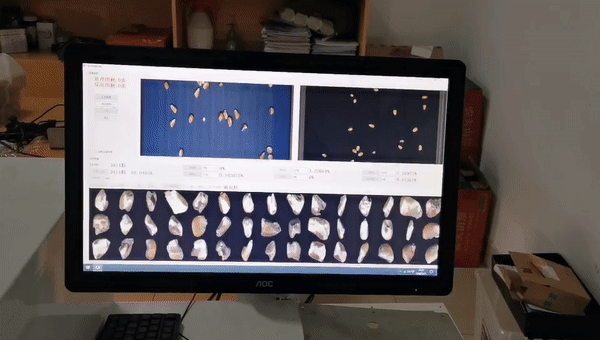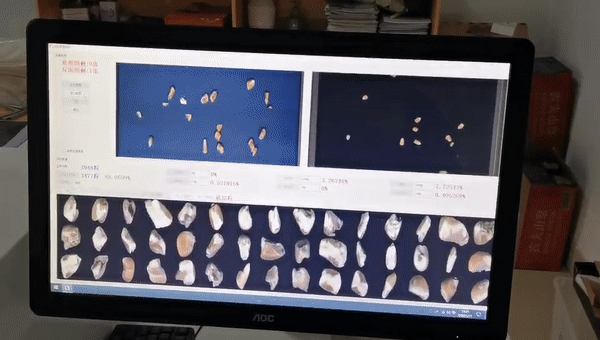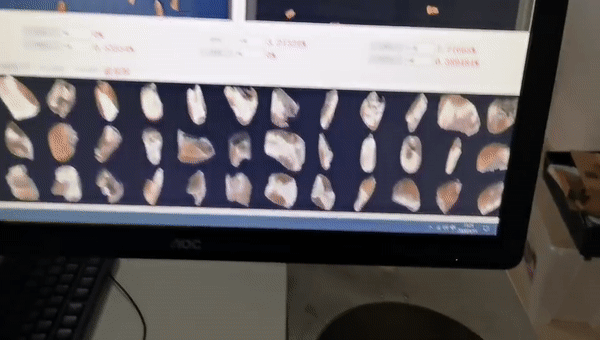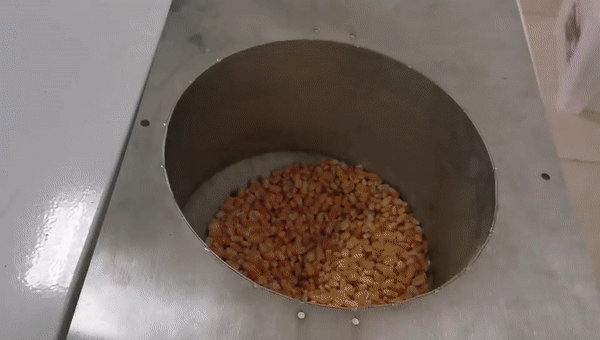
品质分析类,用于传统粮食行业(只分析,不选)

分选类,用于农产品检测行业
下面有几个典型案例跟大家分享一下,首先是印刷行业的案例,我们设计了一种基于比对的印刷缺陷检测,这种比对跟传统比对不一样,会有稍微的偏移,目前在柔性印刷和纺织行业应用得比较多。

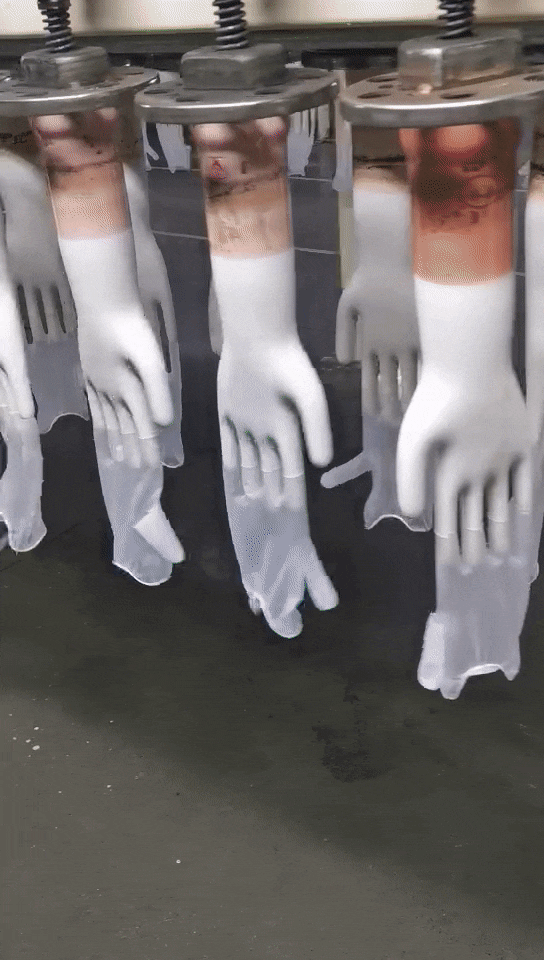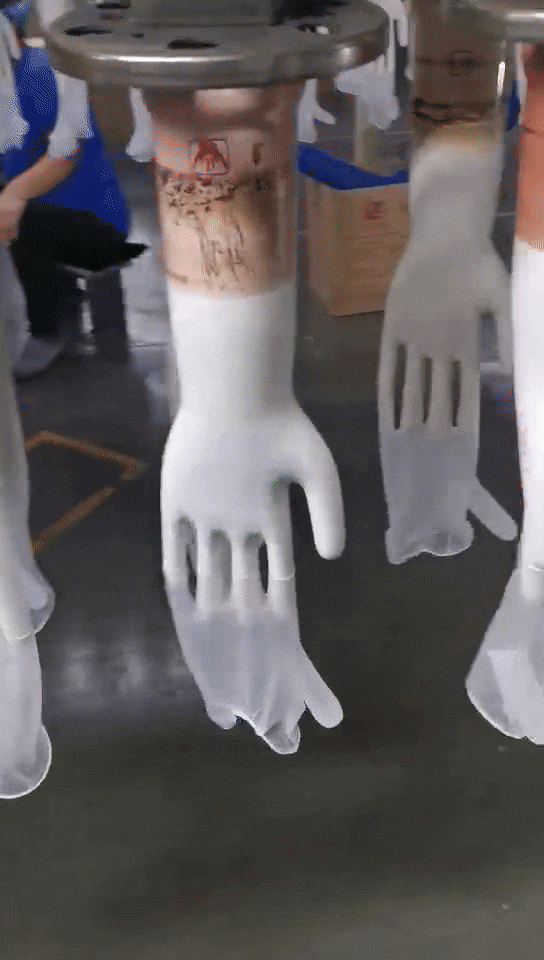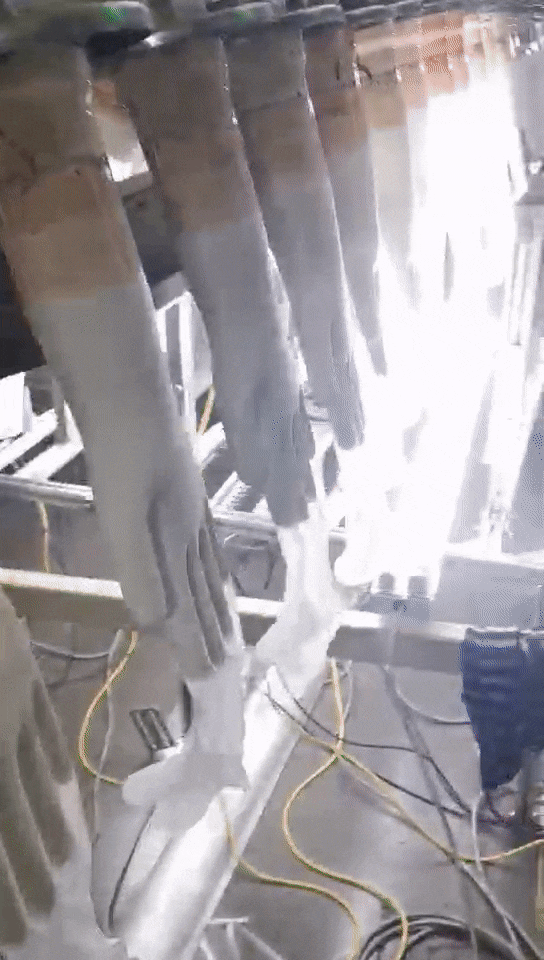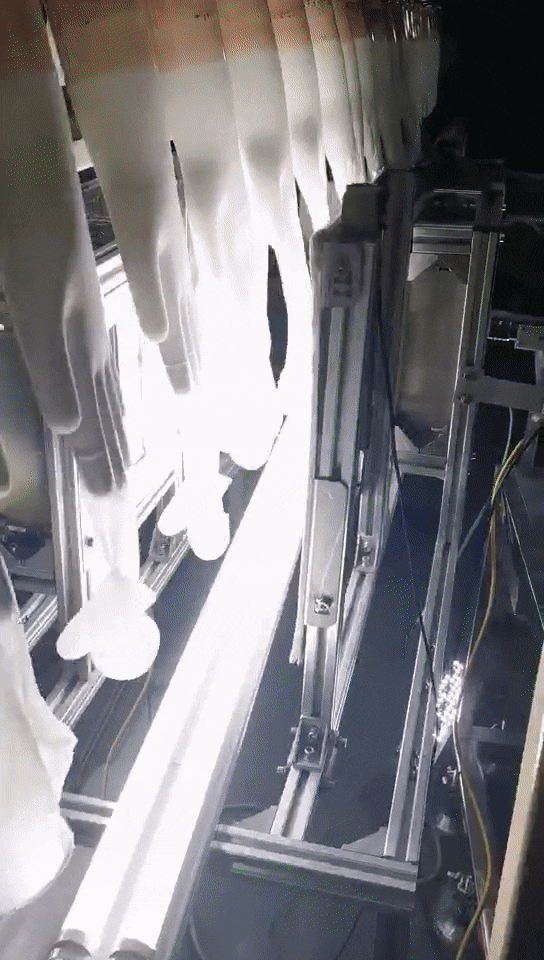
这是应用手套行业的案例,这种应用场景恶劣,现场环境温度有50多度,手膜温度有200度,人在这种环境下是非常难受的,用工控机来做也不现实,受不了这样的高温,我们用的是MIIVII EVO Xavier,它完全可以适应这种恶劣环境,已经应用一年多了,运行还比较稳定。
这是粮食行业品质分析的案例,我们根据国标对每一粒玉米进行分级,虽然皮带运动速度是比较快的,但算力非常充沛,可以达到很高的精度。我们基于这个设备开发了10多款产品,取得非常不错的成绩。
最后,欢迎大家来与科亿一起合作,把AI真正落地,谢谢大家。


 High performance edge device for autonomous machine based on jetson AGX ORIN.Will release on Q1 2023BASED ON MODULEBASED ON APPLICATION
High performance edge device for autonomous machine based on jetson AGX ORIN.Will release on Q1 2023BASED ON MODULEBASED ON APPLICATION MIIVII provides customized services to develop competitive products for different application scenarios.
MIIVII provides customized services to develop competitive products for different application scenarios.

